
Development of a Deep Learning-Based Text-To-Speech System for the Malang Walikan Language Using the Pre-Trained SpeechT5 and Hifi-GAN Models
Author's Country: Indonesia
DOI:
https://doi.org/10.36805/bitcs.v6i2.10314Keywords:
HiFi-GAN, Malang Walikan Language, SpeechT5, Text-to-Speech, Word Error RateAbstract
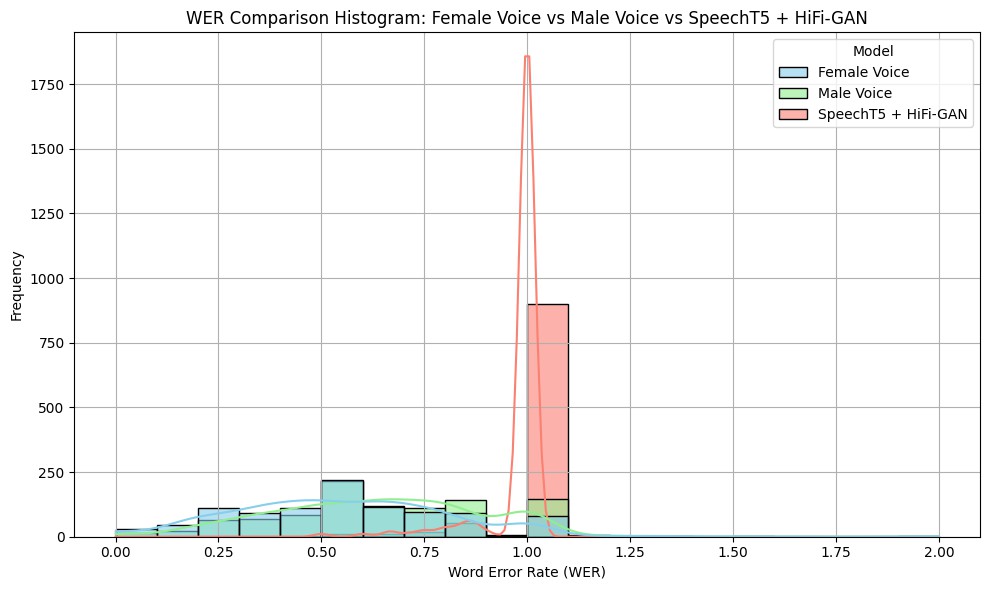
The Walikan language of Malang is a form of local cultural heritage that needs to be preserved in the digital era. This study aims to develop and evaluate a deep learning-based Text-to-Speech (TTS) system capable of generating speech in the Walikan language of Malang using pre-trained SpeechT5 and HiFi-GAN models without fine-tuning. In this system, SpeechT5 is used to convert text into mel-spectrograms, while HiFi-GAN acts as a vocoder to generate audio signals from the mel-spectrograms. The dataset used consists of 1,000 sentences in the Walikan language of Malang. The system evaluation was carried out using objective metrics of Word Error Rate (WER) and Character Error Rate (CER), by comparing the results of synthetic audio transcriptions against two types of reference audio, namely the original voices of female speakers and male speakers, using the Automatic Speech Recognition (ASR) system. The female voice was recorded with controlled articulation, while the male voice used natural intonation in everyday conversation. The results show that synthetic audio has the highest error rate with a WER of 0.9786 and a CER of 0.9024. Meanwhile, female audio has a WER of 0.5471 and a CER of 0.1822, while male audio shows a WER of 0.6311 and a CER of 0.2541. These findings indicate that the TTS model without fine-tuning is not yet capable of producing synthetic voices that can be recognized accurately by the ASR system, especially for regional languages that are not included in the initial training data. Therefore, the fine-tuning process and the preparation of a more representative dataset are important so that the TTS system can support the preservation of the Walikan Malang language more effectively in the digital era.
Downloads
References
J. Lehečka, Z. Hanzlíček, J. Matoušek, and D. Tihelka, “Zero-Shot vs. Few-Shot Multi-speaker TTS Using Pre-trained Czech SpeechT5 Model,” pp. 46–57, 2024, doi: 10.1007/978-3-031-70566-3_5.
H. Wang, “Understanding Zero-shot Rare Word Recognition Improvements Through LLM Integration,” 2025, [Online]. Available: http://arxiv.org/abs/2502.16142
A. Kirkland, S. Mehta, H. Lameris, G. E. Henter, E. Szekely, and J. Gustafson, “Stuck in the MOS pit: A critical analysis of MOS test methodology in TTS evaluation,” no. August, pp. 41–47, 2023, doi: 10.21437/ssw.2023-7.
J. Ao et al., “SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing,” Oct. 2021, [Online]. Available: http://arxiv.org/abs/2110.07205
J. Kong, J. Kim, and J. Bae, “HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis,” Oct. 2020, [Online]. Available: http://arxiv.org/abs/2010.05646
J. Su, Z. Jin, and A. Finkelstein, “HiFi-GAN: High-Fidelity Denoising and Dereverberation Based on Speech Deep Features in Adversarial Networks,” Jun. 2020, [Online]. Available: http://arxiv.org/abs/2006.05694
Z. Qiu, J. Tang, Y. Zhang, J. Li, and X. Bai, “A Voice Cloning Method Based on the Improved HiFi-GAN Model,” Comput Intell Neurosci, vol. 2022, 2022, doi: 10.1155/2022/6707304.
D. Lim, S. Jung, and E. Kim, “JETS: Jointly Training FastSpeech2 and HiFi-GAN for End to End Text to Speech,” Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, vol. 2022-Septe, pp. 21–25, 2022, doi: 10.21437/Interspeech.2022-10294.
A. Ali and S. Renals, “Word error rate estimation without asr output: E-WER2,” Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, vol. 2020-Octob, pp. 616–620, 2020, doi: 10.21437/Interspeech.2020-2357.
A. Ali and S. Renals, “Word Error Rate Estimation for Speech Recognition: e-WER,” Jul. 2018. [Online]. Available: https://github.com/qcri/e-wer
I. Kottayam and J. James, “Advocating Character Error Rate for Multilingual ASR Evaluation,” 2023.
C. Agustina, “IMPLEMENTASI TEKNOLOGI TEXT TO SPEECH BAHASA BANJAR MENGGUNAKAN METODE VITS,” (Doctoral dissertation, Universitas Islam Negeri Sultan Syarif Kasim Riau)., 2024.
M. Y. ALHUDA, “TEXT TO SPEECH BAHASA PALEMBANG MENGGUNAKAN METODE VITS,” (Doctoral dissertation, UNIVERSITAS ISLAM NEGERI SULTAN SYARIF KASIM RIAU)., 2025.
Downloads
Published
Issue
Section
License
Copyright (c) 2025 Aina Avrilia Imani, Aviv Yuniar Rahman, Firman Nurdiyansyah

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.

This work is licensed under a Lisensi Creative Commons Atribusi-BerbagiSerupa 4.0 Internasional.


